Goals:
Walk through a options within a Jupyter Notebook session
Initial Screen Navigation and Options
Upon connecting, you are presented with a simple Jupyter Notebook screen and just a few options:
|  |
|---|
Drop-Down Menu Bar
|  |
|---|
Active Work Area
Whatever you’re currently working on
|  |
Opening a New Blank Notebook
From the Dropdown: File->New->Notebook |  |
|---|---|
From the Right side of the File Management Tab: New->Notebook |  |
Kernels
A Jupyter kernel is the computational engine behind the code execution in Jupyter notebooks.
Most users think of this as the “compiler” or programming language used when running code cells.
The Kernel empowers you to execute code in different programming languages like Python, R, or Julia or others and instantly view the outcomes within the notebook interface.
After opening a new notebook, you will be prompted to select a kernel
|  |
Default Kernels on ARCC HPC Resources include:
HPC-wide kernels are titled by packages installed and available when launched Users can also create user-defined kernels from conda environments (Covered in a subsequent module. See Creating Jupyter Kernels from Conda Environments) |   |
Running a Jupyter Notebook with Python 3 Kernel
If we select the default Python 3 (ipykernel), we are presented with the file explorer showing our home directory as it’s root location.
| 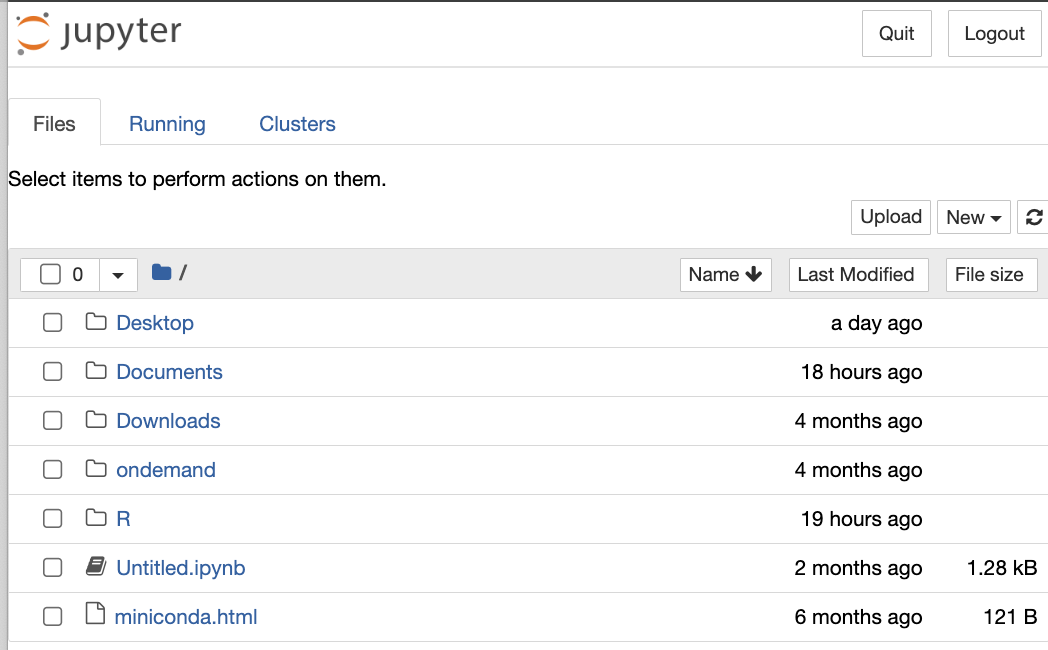 |
|
|

What Packages are Available in our Kernel?
In our notebook, we can write out a simple a python command that will list available packages:  After writing this command, we hit the “play” button to run this cell:  Click on the package list image to the right to see output At first glance, it looks rather comprehensive. We have a long list of software packages available to us. |  |
New Cell in our Notebook
After running our last cell, a new cell is automatically created at the bottom extending our notebook
New empty cell is at the bottom.
Previous cell and output from that previous cell’s run is above our new cell
We can also manually create a new cell with the + button
In this cell, lets run another python command to import a common package used in mathematic and multi dimensional matrix computations - numpy.

Then run it like we did the last cell.
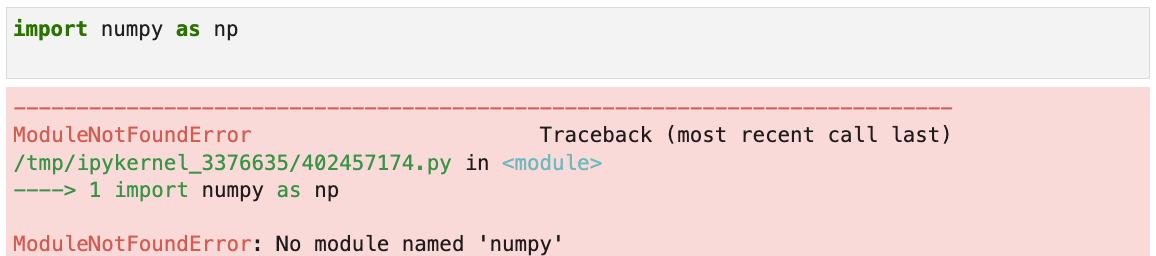
This error message indicates the numpy package isn’t installed, despite being a commonly used software package.
Our first cell’s output appears to be misleading. The listed packages are installed, but they are all needed simply to run Jupyter.
Most software we’d need to perform even more simple and common activities for our research would still need to be installed or made available somehow.
Load a different kernel
Depending on the HPC’s native environment, you may have other kernels available.